Internet Archive Now Contains 400 Billion Webpages
The Internet Archive has announced that its "Wayback Machine" collection of archival Web pages has surpassed the 400 Billion mark. This is a significant increase from the first time we wrote about the Archive, shortly after it was released publicly in 2001, when it contained approximately 10 Billion Web pages.
The Internet Archive gives us access to old versions of pages that have been collected and stored on its servers. Subsequent changes made to the "live" version of the Web page do not effect the version stored in the Archive's collection. Searching the Archive gives us the ability to see what Web pages looked like in the past.
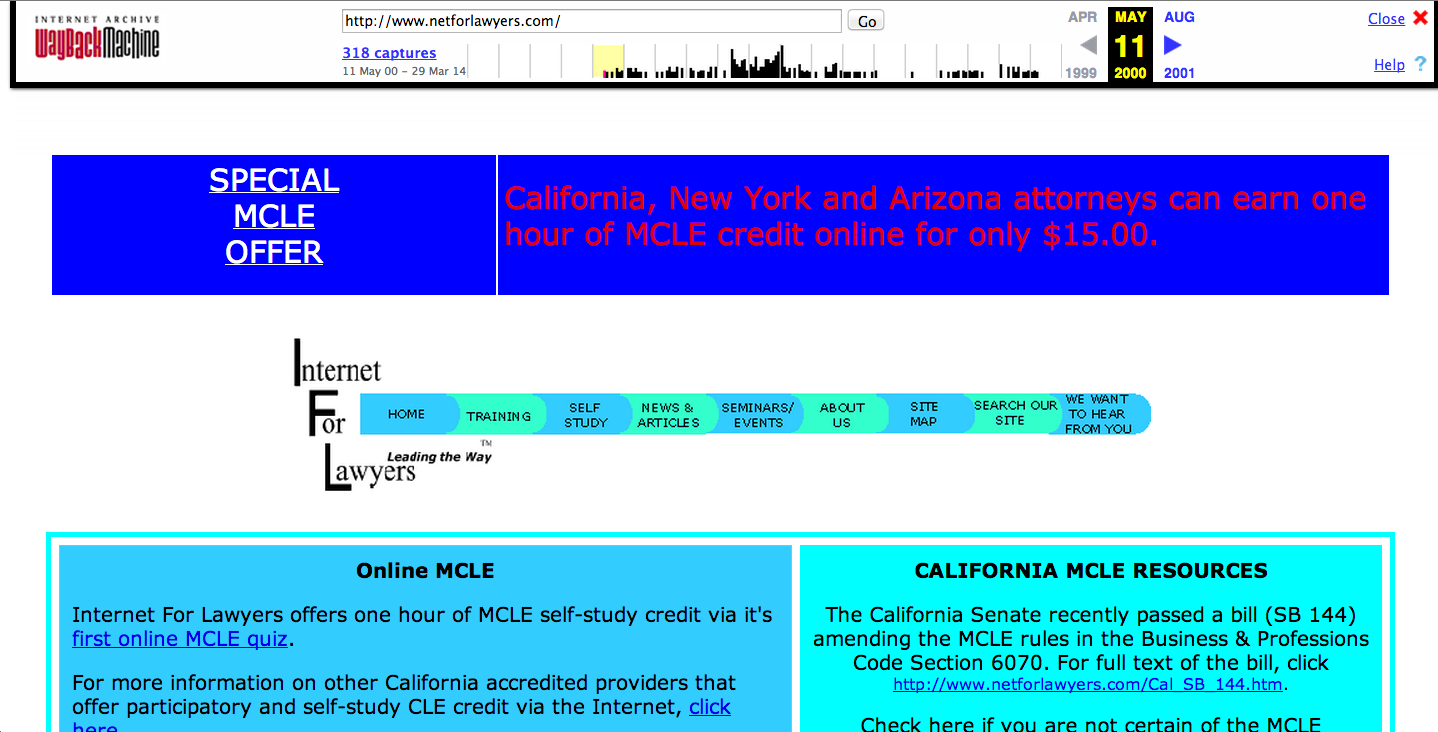
| May 11, 2000 | September 30, 2005 |
 |
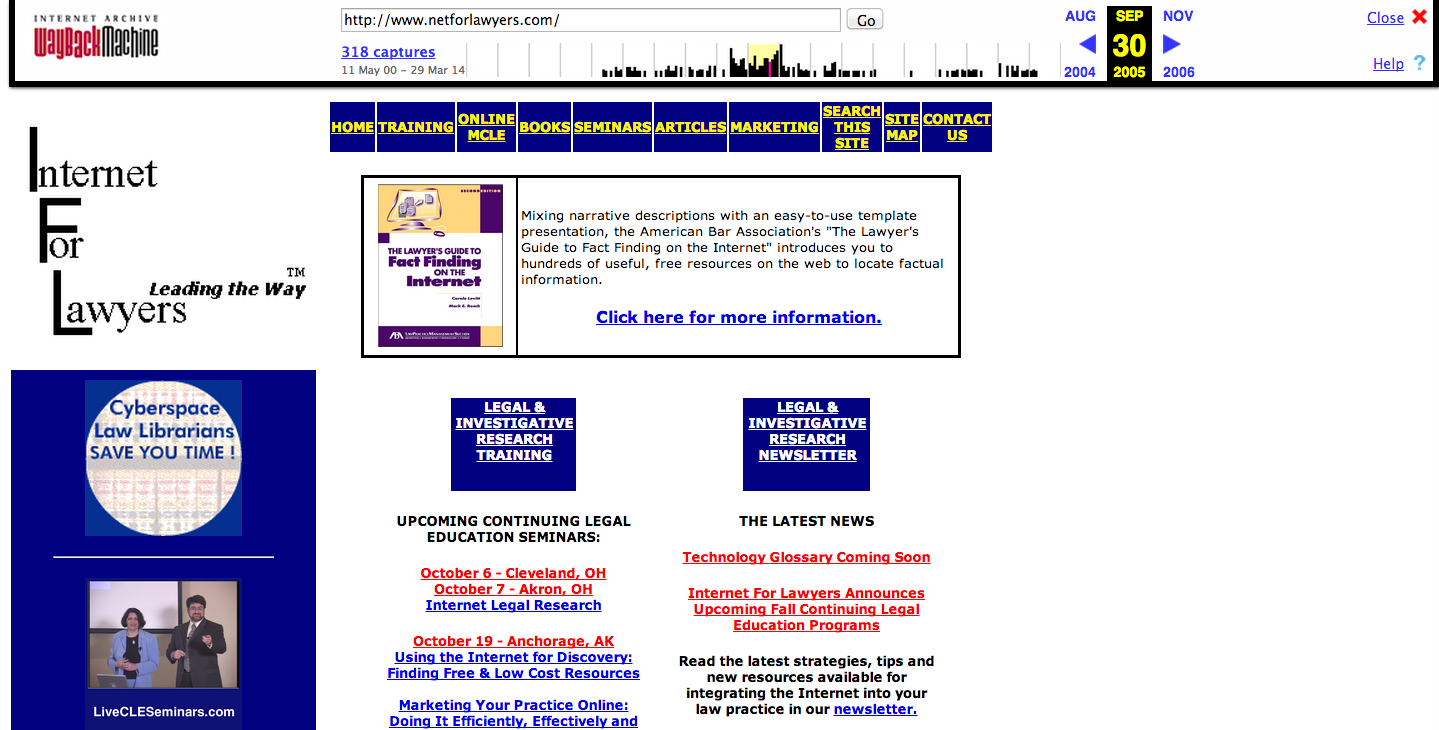 |



While the Internet Archive collection wasn't launched publicly until 2001, it actually began collecting Web pages in 1996. Unlike some of the traditional search engines that offer access only to the most recent cached versions of the old Web pages they’ve captured, the Way Back Machine offers access to all of the versions of any Web page it has captured. To locate any of these old pages, you must enter the URL of the specific site (or page) you’re interested in locating into the search box on Archive.org’s home page and click the "Browse History" button. (It is important to note, however, that you cannot do a keyword search through this collection of pages)
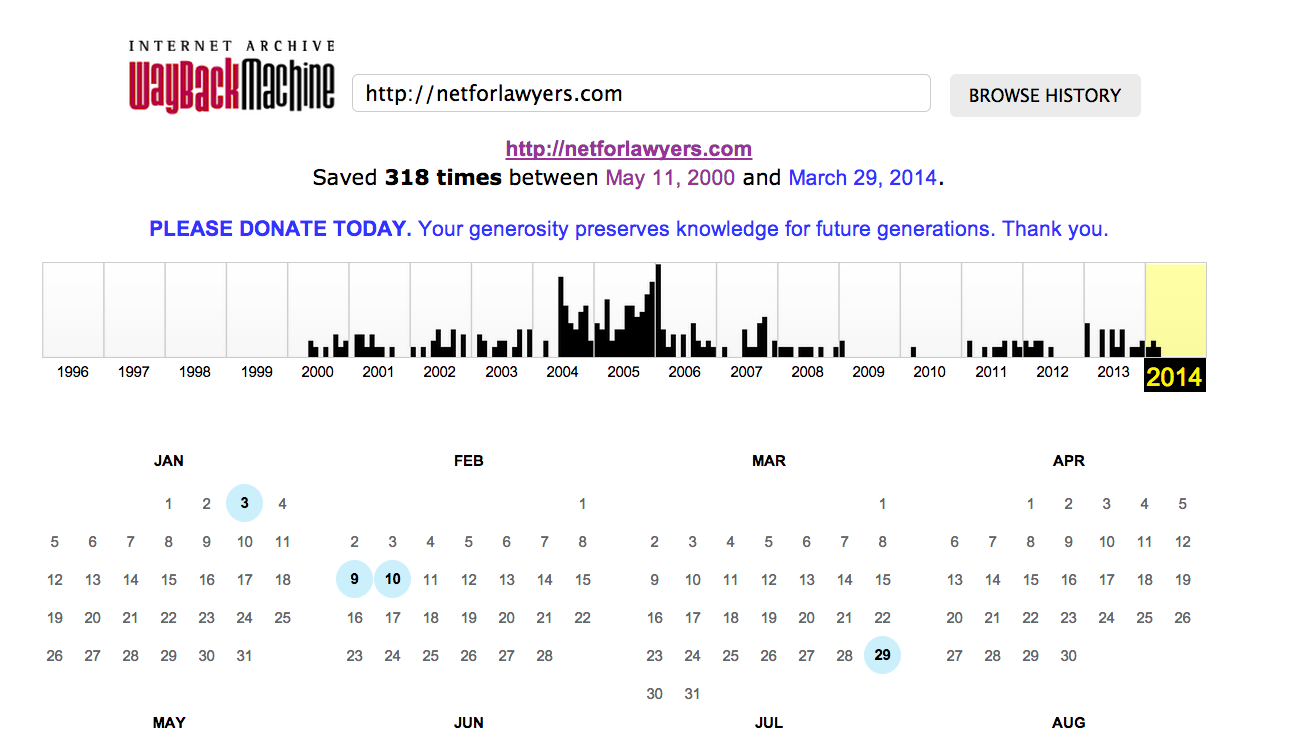
The search results will display a calendar list of the most recent captures of the URL searched for that are available in the Archive.org collection. Each blue dot on the calendar represents a day on which the searched URL was crawled. The larger the blue dot is, the more snapshots of content from that URL were captured on that day. Clicking on any of the blue dots will display that old Web page as it appeared on the date selected.
The timeline at the top of the calendar graphically depicts the distribution of all captures for the searched URL. Clicking on any of the years in the timeline will then display all of the captures for the searched URL for the year selected. The timeline also lists the number of times the searched URL has been crawled by Archive.org and the earliest date on which the URL was crawled. Note, however, that in our test searches clicking on a year where no captures were displayed in the timeline occasionally returned a cached page from Archive.org’s collection.